IPinfo Lite offers unlimited country-level IP geolocation with basic ASN data while our paid plans come with limited API requests per month.
One simple way to reduce your request volumes and squeeze some extra value our of our API is to avoid doing lookups for known bots, such as the Google or Bing search bots which crawl websites and can generate a lot of additional requests.
Filtering out bot traffic is easily done by looking at the user-agent header. Here are some user agents for common bots:
| SEARCH BOT | USER AGENT |
|---|---|
| Google Bot | Googlebot/2.1 (+http://www.googlebot.com/bot.html) |
| Bing Bot | Mozilla/5.0 (compatible; bingbot/2.0 +http://www.bing.com/bingbot.htm) |
| Yandex Bot | Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) |
| Baidu Spider | Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) |
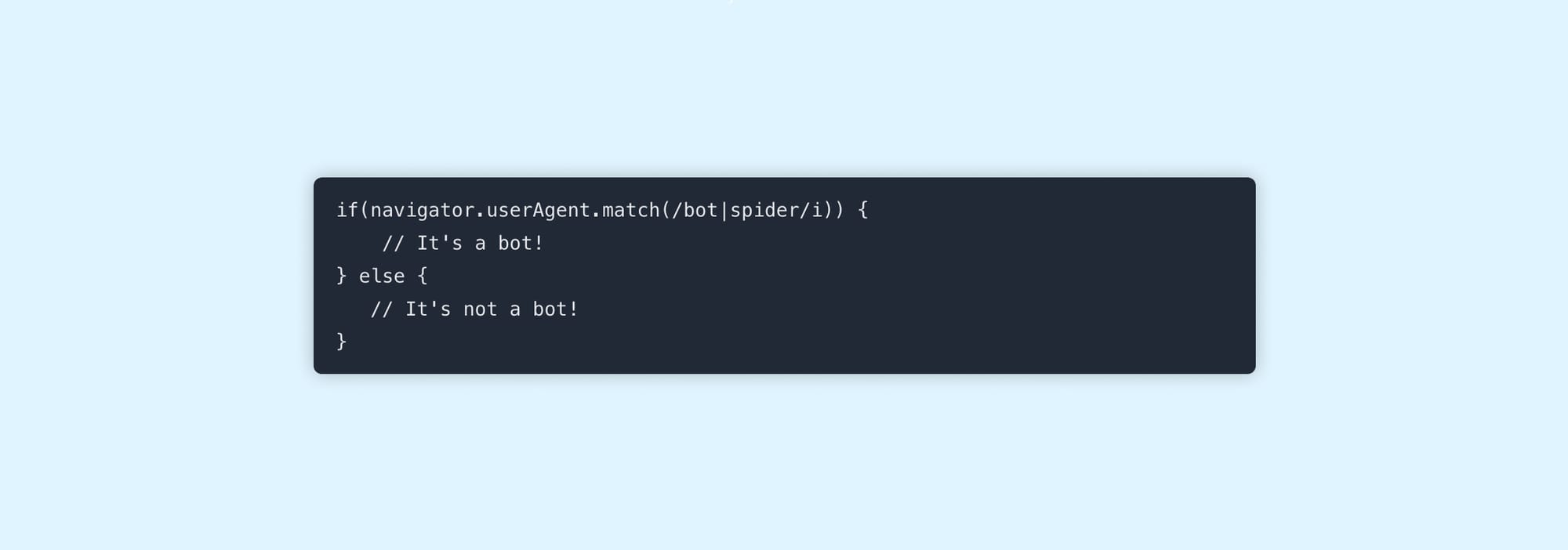
Notice that they all contain the term "bot" or "spider". Here's a little javascript snippet that uses a regular expression to look for these terms, and performs a different action based on what it finds:
if(navigator.userAgent.match(/bot|spider/i)) {
// It's a bot!
} else {
// It's not a bot!
}
That check can then be used to avoid hitting the IPinfo.io API for bots, by doing something like this:
if (navigator.userAgent.match(/bot|spider/i)) {
// It is a bot. We might want to set some defaults here, or do nothing.
} else {
// It's not a bot! Hit the API
const request = await fetch("https://ipinfo.io/json?token=$TOKEN");
const jsonResponse = await request.json();
console.log(jsonResponse);
}IPinfo is a comprehensive IP data and API provider with flexible pricing plans to meet your business needs. We handle billions of API requests per month, serving data like IP geolocation, VPN detection, IP to company, and more. Sign up for a free account or contact our data experts to learn more.
About the author

Internet Data Expert