
Reducing IPinfo.io API latency 50x by making rDNS lookups blazingly fast
Get Unlimited Access to IPinfo Lite
Start using accurate IP data for cybersecurity, compliance, and personalization—no limits, no cost.
Sign up for freeWe receive over 40 billion requests to our IP address API every month, and we go to great lengths to ensure that our data is accurate and that our service is reliable and fast.
One of the key things that helps us to be both reliable and fast is to do almost all of our data processing offline and then write the summarized results to binary files, which our API servers can read into memory. This allows us to move the data processing complexity off of the web servers, and out of the critical request-response cycle, so that our API nodes can be fairly “dumb” and not do much more than read data from memory and return it, based on the IP address that’s being looked up. This also allows us to scale easily, and each API node has a full copy of the data it needs for the API, so as we get more traffic, new servers are added automatically.
Our only exception to the offline data-processing approach has been reverse DNS lookups, which populate the hostname field of our API response. We were resolving these in real-time, which would add up to 200ms to our API response time when requesting all details. After some brainstorming, we shifted to an offline approach, which reduced latency in some cases by more than 50x, but let’s talk about what rDNS is and why anyone should even care about it.
What Is rDNS?
rDNS, or reverse DNS, is the opposite of “normal” (forward) DNS. Forward DNS maps domain names to IP addresses, and reverse DNS maps IP addresses to hostnames and domain names. To better understand the importance of rDNS, let’s first take a layman’s approach to forward DNS.
Every time we navigate to a domain name, such as google.com, our browser has to resolve the domain’s IP address to know which page to send us to. A DNS record is what allows a short and simple domain name to point to a long and complicated IP address. Think of a DNS record as an address book entry — it’s much easier to remember someone by their name rather than their home address.
For example, 172.217.15.110 is an IP address that currently belongs to Google. Visiting this IP address or google.com, in a web browser, will bring us to the same page, but one is much easier to remember. This is a convenience provided by forward DNS.
However, reverse DNS is more complicated than simply flipping forward DNS. Actually, the two are completely separate.
In 1985, a special domain, in-addr.arpa, was created and reserved for the DNS namespace to provide a reliable way to perform reverse queries through zoning. Without it, the only way to reverse query would be to search through all domains in the entire namespace. This would take too long and require an excessive amount of processing.
Building this reverse namespace requires that subdomains are formed using the reverse ordering of numbers (by each dotted decimal) in each IP address, thus creating zones. This is efficient since the last octets of an IP address are the most telling of its specific information, such as host address. For example, Google’s reverse lookup zone for 172.217.15.110 is 110.15.217.172.in-addr.arpa.
The in-addr.arpa domain tree also requires a special resource type, a PTR (pointer) record, to be defined. This record creates a mapping in the reverse lookup zone that typically corresponds to an A record for the DNS computer name of a host in its forward lookup zone.
While rDNS can be tough to fully understand and appreciate at a technical level, the ways in which we benefit from it are much clearer.
Why Is rDNS Important?
First and foremost, an IP address’s hostname provides plenty of at-glance information. For residential IPs, the hostname is often telling of the ISP, geolocation, and other general details. For systems that identify devices by IP address, this can be extremely useful.
Reverse DNS can also be used to verify that an email does not originate from a malicious sender. If the sender does not have a reverse DNS record at all, that’s often a bad sign, and the email will thus be rejected by most secure email servers. If the sender does have a reverse DNS record, you can further validate the sender by verifying that the record matches the domain name they’re sending from.
The existence of rDNS also enables forward-confirmed reverse DNS, which is a form of authentication that helps validate the relationship between the owner of a domain and an IP address. This is often used when creating whitelists to protect against spam, phishing, and other malicious activity.
Reverse DNS can also be used to authenticate web crawlers such as Googlebot, as explained by Google here. Since user agents can be spoofed, rDNS is an effective way of verifying Googlebot as the caller.
rDNS Lookups at IPinfo
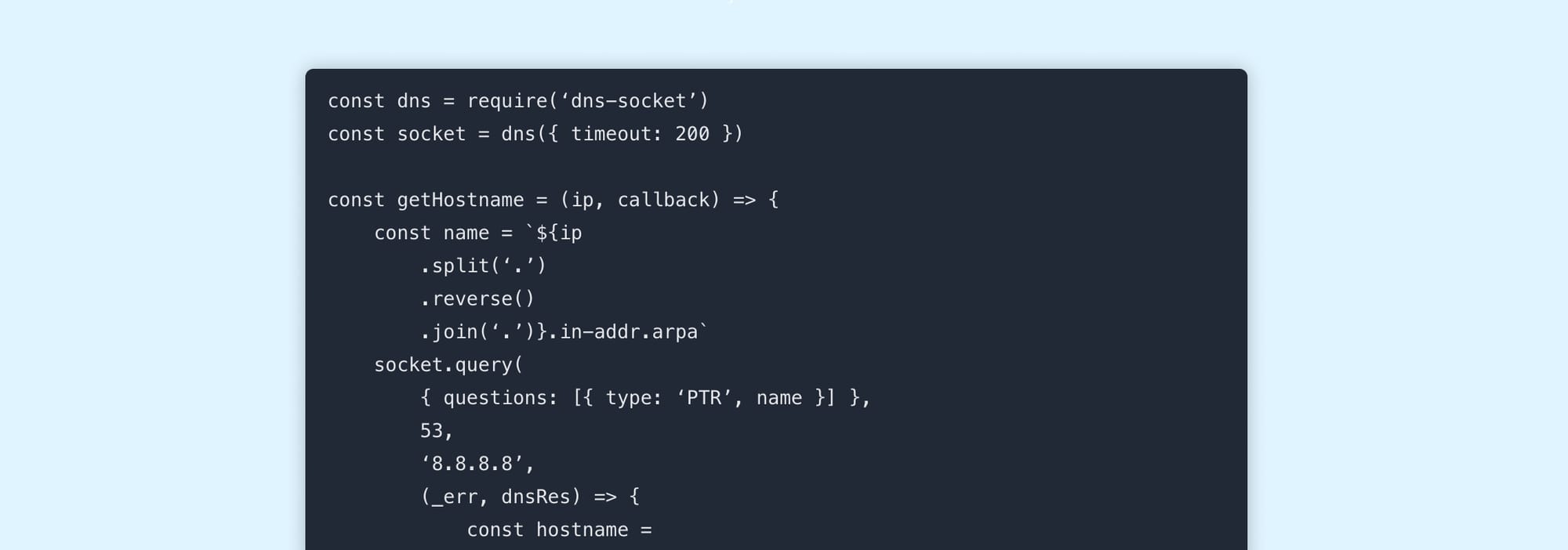
Until recently, we would process rDNS lookups on the fly as each request was made, capped at 200ms. This required us to write custom code because the Node.js DNS library doesn’t include a timeout or allow us to set the resolver.
const dns = require(‘dns-socket’)
const socket = dns({ timeout: 200 })
const getHostname = (ip, callback) => {
const name = `${ip
.split(‘.’)
.reverse()
.join(‘.’)}.in-addr.arpa`
socket.query(
{ questions: [{ type: ‘PTR’, name }] },
53,
‘8.8.8.8’,
(_err, dnsRes) => {
const hostname =
dnsRes &&
dnsRes.answers &&
dnsRes.answers[0] &&
dnsRes.answers[0].data
? dnsRes.answers[0].data
: null
callback(null, hostname)
}
)
})With all other data being read directly from memory, the rDNS lookup was by far the slowest part and placed a limit on how much we would be able to improve the latency of our API, therefore we wanted to find a way to avoid doing the lookup at request time. One solution we considered was to eliminate the hostname field and avoid the lookup altogether. This would make things quicker, but we’d also be removing information that some people find really useful.
Another option we considered was to make it an optional extra, which could be enabled or disabled via a setting or query parameter. We couldn’t think of a good default setting, though. If we were to disable the hostname field by default, then the API would be quicker, but because of the power of defaults, most people would never find out about the option and enable it, so it wouldn’t be much better than not having the field at all. Additionally, if the default was to leave it on, then again, due to the power of defaults, most people would still have a slower API response and possibly not find the setting to disable it. Once we’d ruled out those options, we set about finding ways to make the lookup quicker.
Making It Faster
To get hostnames we clearly need to resolve the IP address to a name at some point. We started by resolving all IP addresses to their hostnames in bulk. The resulting data set was just over 50GB, and looked like this:
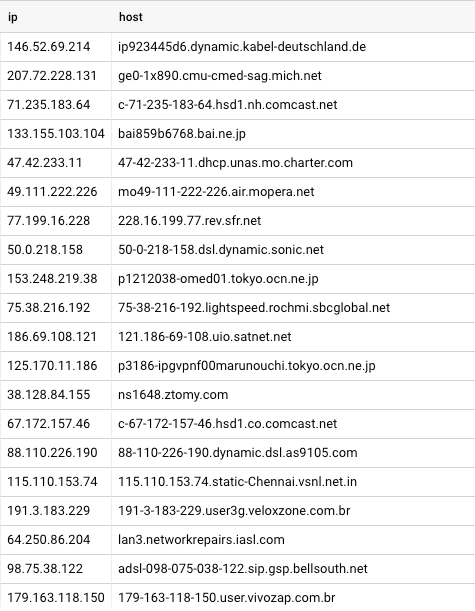
At lower request volumes, it’d be possible to put all of these into a SQL database and simply query for the hostname from the database at request time. However, at the request volumes we get, that’d put too much load on a single database and would give us a single point of failure.
Our goal was to be able to load the full data set into memory on all of our API nodes, removing any point of failure, and also making the lookups much faster. Loading 50GB of data into memory would be prohibitively expensive, though, so we looked for ways that we could group the rDNS data, allowing us to compress multiple entries in the data to a single record that we could then reconstruct back into the full hostname at request time, like this:

For example, all of those IP addresses (and many more on the same ISP) have a common string in their hostname (red-79–156–9.staticip.rima-tde.net), prefixed with the last octet of the IP address. We can replace all of those records with a single record that looks something like this: 79.156.0.230–236: $lastoctet.red-79–156–9.staticip.rima-tde.net
We can then get the full name by replacing $lastoctect with the actual last octet from the IP address.
We spent a lot of time analyzing the hostname data and looking for patterns like the one above. There are some obvious ones, like the IP address being included in the hostname, or a reversed copy of the IP address in the hostname. There are also some less obvious ones, like a hexadecimal version of the IP in the hostname, or an offset number being included in the hostname.
After a lot of experimentation, we were able to create two generalized replacement rules that cover almost all of the different cases.
First, IP octets in decimal and hexadecimal representation are replaced by placeholders. For example, <i> stands for the first octet in decimal notation, <j> for the second, <m> for the first octet in hexadecimal notation, etc. Often, there is more than one way to do this — for instance, one- or two-digit octets, repeating octets, and hexadecimal octets are problematic. For each hostname, we try several replacement orders and pick the one that applies the most replacements.
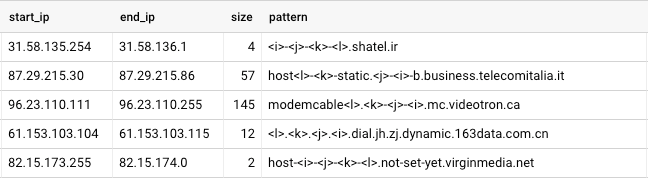
Our other rule deals with hostnames that contain an incrementing offset for consecutive IP addresses. For example, the block of 37.225.0.0–37.225.237.17 contains 60,690 IP addresses, and their hostnames contain an incrementing number, starting at 547007.
$ host 37.225.0.0
0.0.225.37.in-addr.arpa domain name pointer public-gprs547007.centertel.pl.
$ host 37.225.0.1
1.0.225.37.in-addr.arpa domain name pointer public-gprs547008.centertel.pl.
$ host 37.225.0.2
2.0.225.37.in-addr.arpa domain name pointer public-gprs547009.centertel.pl.
$ host 37.225.237.17
17.237.225.37.in-addr.arpa domain name pointer public-gprs607696.centertel.pl.In this block, we encode hostnames as public-gprs<OFFSET:-634955585>.centertel.pl. To convert the IP to hostname, we take the IP, convert it to an integer, and add it to the number following the colon (:). For example, 37.225.0.2 is 635502594: 635502594 + (-634955585) = 547009.
After applying these two replacement rules on our data set, we have a table that shows the IP address, hostname, and resulting pattern that we have, after applying the replacements, like this:
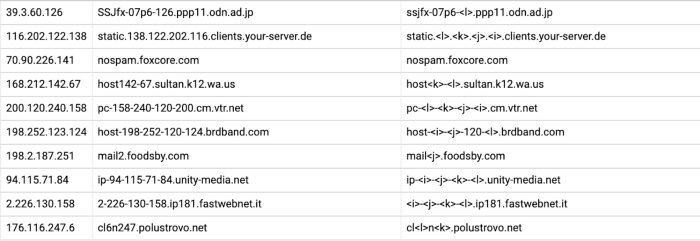
The next step is to group the data into ranges, so that consecutive IP addresses with the same pattern end up as a single row. To achieve that, we use BigQuery analytic functions in a query that looks like this:
SELECT NET.IP_TO_STRING(NET.IPV4_FROM_INT64(start_ipint)) AS start_ip
, NET.IP_TO_STRING(NET.IPV4_FROM_INT64(end_ipint)) AS end_ip
, GREATEST(end_ipint — start_ipint, 1) AS size
, host
FROM (
SELECT MIN(ipint) AS start_ipint, MAX(ipint) AS end_ipint, host
FROM (
SELECT *, ipint — rank AS _group
FROM (
SELECT *,
DENSE_RANK() OVER (PARTITION BY host ORDER BY ipint) AS rank
FROM import.rdns_norm_domain
)
)
GROUP BY _group, host
)The resulting data set looks like this and is less than 5GB, down from around 50GB, and is easily loadable into memory:

The Results
As a result of the changes to how we handle rDNS lookups, we’ve been able to significantly reduce the latency on requests to our API.
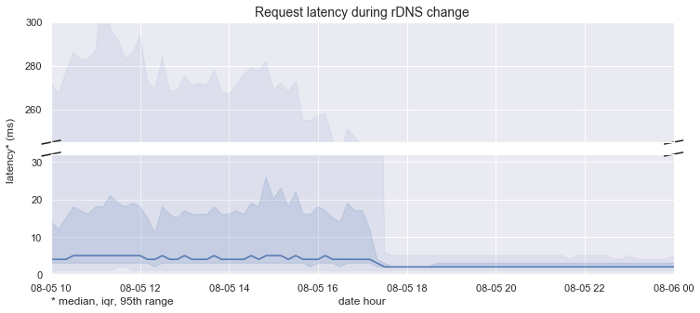
The graph above highlights our median response latencies before and after we deployed the change. We achieved a ~2x speedup in the median case, from 4ms down to 2ms, but a dramatic ~56x speedup in the slow case, from 268ms down to 5ms.
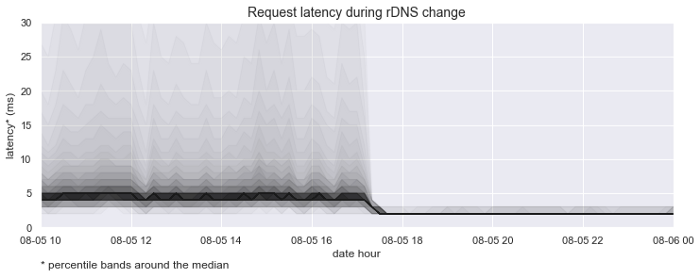
This graph emphasizes the percentile bands around the median request latency. It helps visualize the dramatic improvement in lookup time and consistency.
Our grouped and simplified rDNS data set is now also being used to help us with network topology inference and geolocation hints, helping us improve the accuracy of our geolocation and IP-to-company data sets.
IPinfo is a comprehensive IP address data and API provider with flexible pricing plans to meet your business needs. We handle billions of API requests per month, serving data like IP geolocation, IP to company, IP ranges, and more. Sign up for a free account or contact our data experts to learn more.
Share this article
About the author

Internet Data Expert