
Get Unlimited Access to IPinfo Lite
Start using accurate IP data for cybersecurity, compliance, and personalization—no limits, no cost.
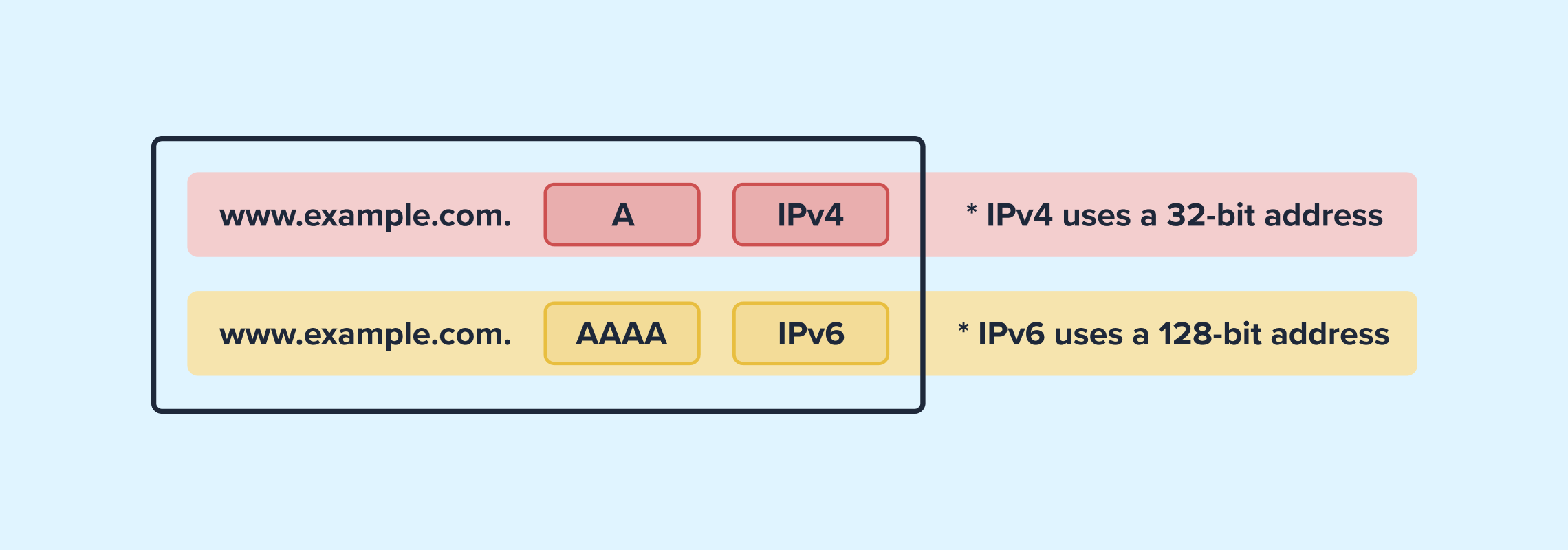
Sign up for freeWhen you type www.example.com into your browser, your device reaches out to a DNS server to resolve that name to an IP address, either IPv4 or IPv6, depending on the network configuration. For dual-stack domains (those with both IPv4 and IPv6), this might mean two addresses pointing to the same web service.
But do these addresses always belong to the same physical host or network segment? And more importantly, when stepping back from individual IPs, can we identify prefix-level relationships across address families?
That’s exactly what Fariba Osali, K. Zubair Sediqi, and I set out to explore, with a focus on identifying what we call sibling prefixes. We presented our findings at the ACM Internet Measurement Conference 2025 in Madison, WI last week.
Why Do Sibling Prefixes Matter?
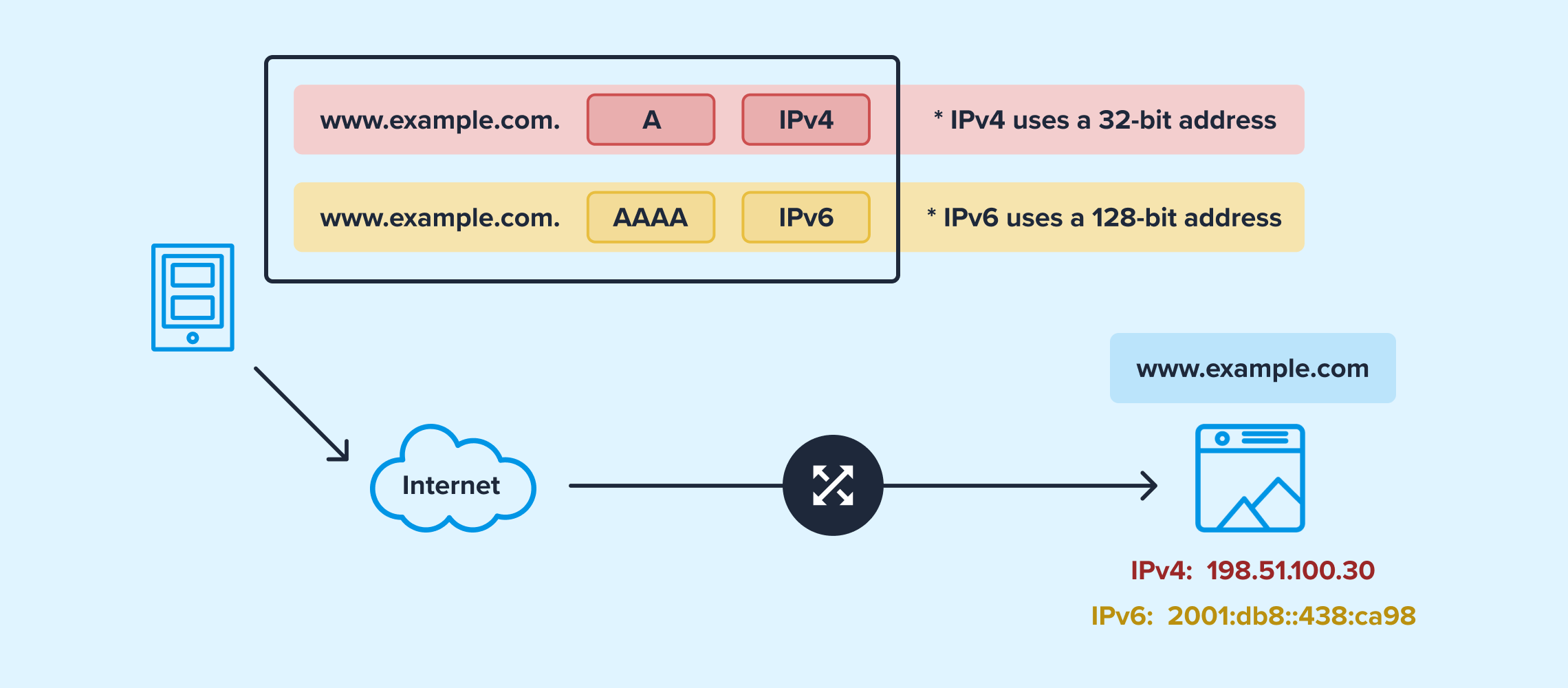
Network operators often manage large IPv4 and IPv6 spaces separately. An operator may have extensive routing, filtering, or security policies for IPv4 prefixes, but not know the corresponding IPv6 ones.
Sibling prefix discovery helps close that gap. If operators know which IPv6 prefixes correspond to their IPv4 ones, they can apply consistent policies, reduce configuration errors, and better secure dual-stack networks. For researchers, these relationships offer a structured basis for cross-family comparisons, from geolocation to threat analysis.
Our Approach to Determining Prefix Pairs
To detect sibling prefixes, we leveraged a large-scale DNS resolution dataset from OpenINTEL, which includes daily DNS records from:
- Cisco Umbrella
- ccTLDs (like .fr)
- Tranco
- Alexa Top 1M
- Cloudflare Radar
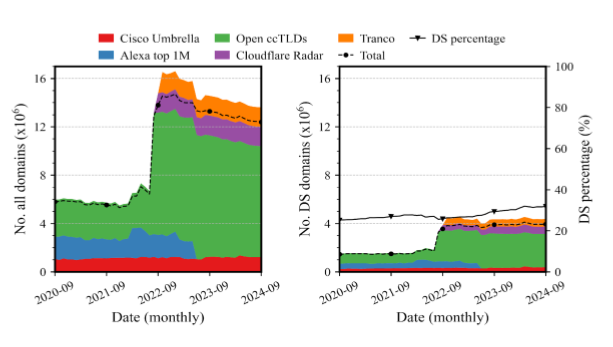
We focused on dual-stack domains, which resolve to both IPv4 and IPv6 addresses. As of our latest snapshot, we worked with nearly 4 million such domains.
From here, the process was:
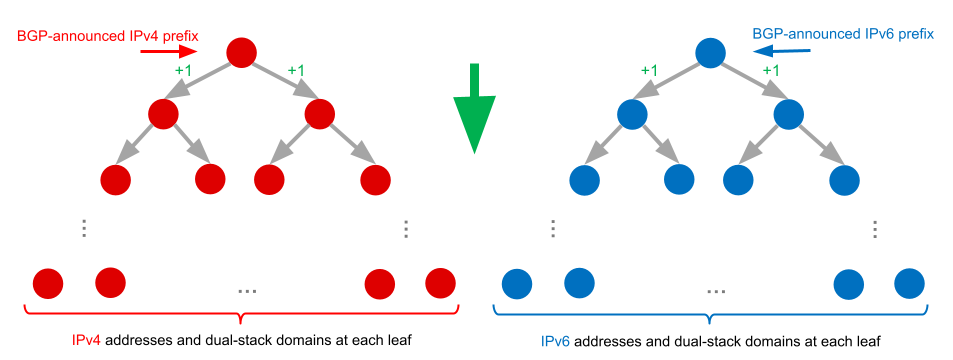
- Map each dual-stack domain to its IPv4 and IPv6 addresses
- Extract the BGP-announced prefixes for each address
- Group domains by prefix
- Compute the Jaccard similarity between IPv4 and IPv6 prefix domain sets
A high Jaccard value (closer to 1) means both prefixes serve many of the same domains, which is our signal for potential siblinghood. With this process, we found 52% perfect match sibling prefixes.
Introducing SP-Tuner for Optimizing Prefix Matching
One challenge: BGP-announced prefixes can vary widely in size. Some are overly broad, others too specific. So we built SP-Tuner, a method to dynamically adjust CIDR sizes to maximize domain similarity.
SP-Tuner uses tree traversal to:
- Iterate through finer-grained prefix levels (e.g., /24 to /28 for IPv4)
- Calculate Jaccard similarity at each step
- Keep refining until no further improvements occur
- Output the most “tuned” sibling prefix pairs
We evaluated SP-Tuner across varying thresholds. The results? More sibling pairs and higher average similarity.
- At /28–/96, over 82% of prefix pairs had a Jaccard similarity of 1.0
- Even with broader /24–/48, 67% had perfect overlap
SP-Tuner helps identify more precise and more relevant sibling prefixes, refining BGP defaults to better reflect operational reality.
Organizational Insights
Finally, we examined whether sibling prefixes originate from the same organization. We used AS ownership metadata to classify each pair as:
- Same Organization: Identical AS or registered under the same name
- Different Organization: Separate registrants
As of September 2024:
- ~46k IPv4 and ~39k IPv6 prefixes formed 76k sibling pairs
- 54% of pairs came from the same organization
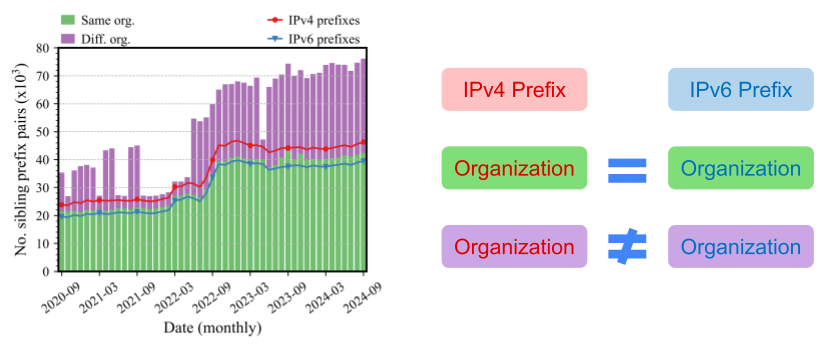
This insight helps network and research communities understand which sibling relationships reflect shared infrastructure, and which might be coincidental or third-party.
Unlocking Greater Precision
Identifying sibling prefixes reveals how IPv4 and IPv6 interact beneath the surface and opens new paths for:
- Policy consistency
- Threat mitigation
- Infrastructure alignment
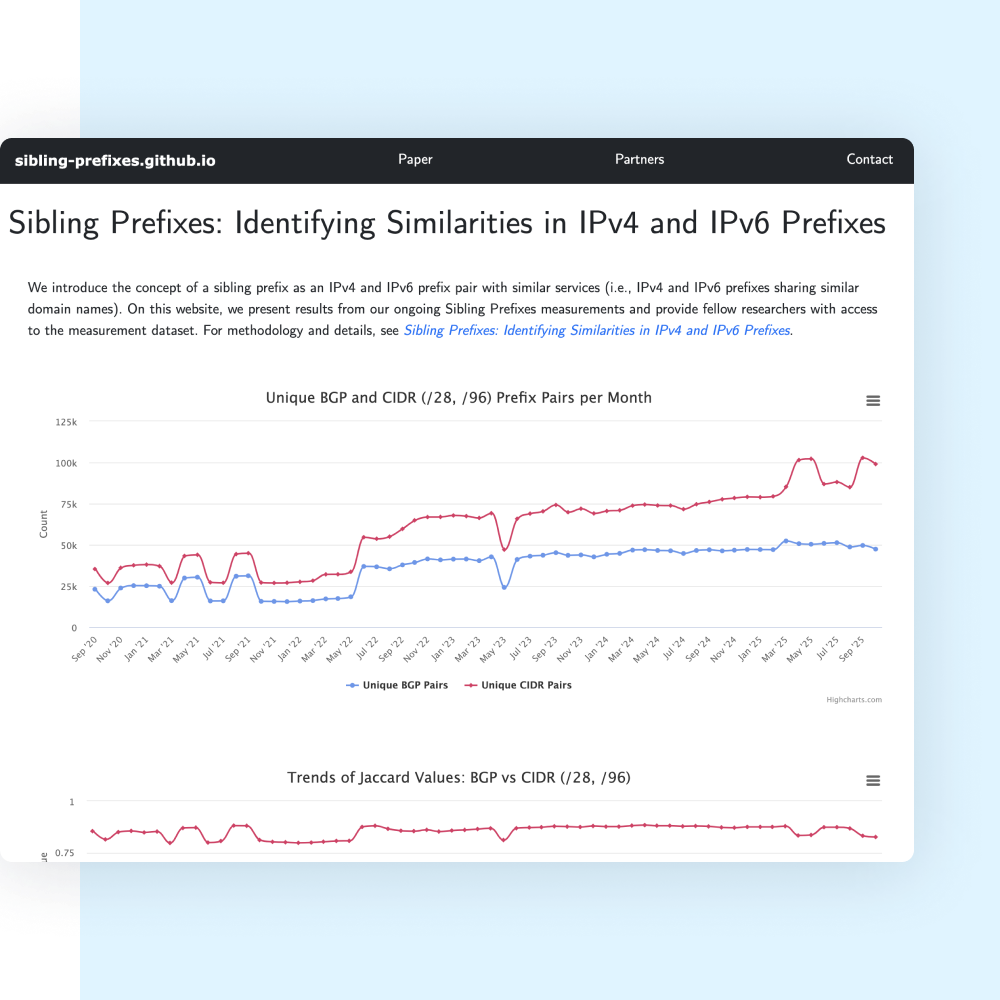
With tools like SP-Tuner, we can not only detect these relationships, but refine them, unlocking greater precision for both operators and researchers. We are running a service to continuously identify sibling prefixes. See the data here.
Dive deeper into the data
Want to learn more about the methodology or our data?
Share this article
About the author

As head of research at IPinfo, Oliver leads IPinfo’s research team, collaborates with academic institutions, and conducts cutting edge research.